Turn your computer into an AI machine - Chat with your documents

Introduction
In the previous blog post I configured Open WebUI to use Ollama for self-hosted models or alternatively Open AI’s API to answer questions, describe images or generate images with DALL-E. Another interesting use-case is “chatting with documents”. That means it’s possible to upload document files like PDFs, Markdown or plain text to Open WebUI which processes the documents to make them available via the chat prompt. This is called RAG. RAG stands for “Retrieval-Augmented Generation.” It’s an approach in AI where a language model, like the ones provided via Ollama or ChatGPT, retrieves relevant information from external knowledge sources (like databases or documents) to enhance its responses. This combined method helps the AI provide more accurate and up-to-date answers by using reliable data, rather than relying solely on its pre-trained knowledge. Using Ollama and the Llama3 models (which are hosted locally) everything is processed locally and no data is sent to Open AI (at least as long as you don’t use a Open AI model).
Configure Open WebUI for RAG
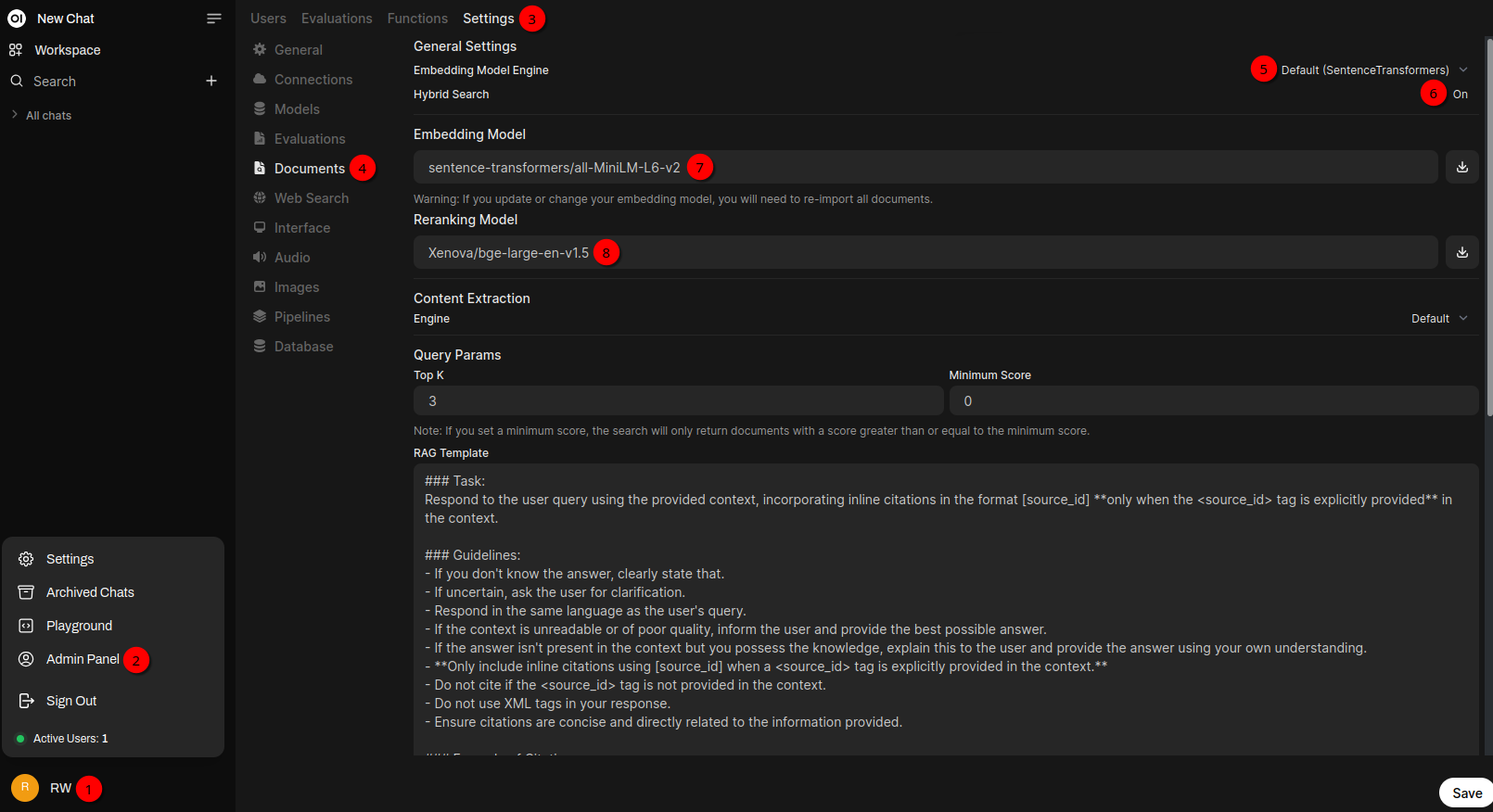
Before being able to chat with documents one need configure Open WebUI accordingly. As in the previous blog posts it’s again clicking on the username 1️⃣ on the bottom left, Admin Panel 2️⃣, Settings 3️⃣ in the tab bar at the top and Documents 4️⃣.
For the Embedding Model Engine I’ll stay with Default (SentenceTransformers) 5️⃣ for now. It’s also possible to use Ollama and OpenAI. If it comes to privacy you most probably don’t want to use OpenAI. I also tried Ollama with the llama3.1:8b embedding model. That worked basically but I had issues with documents of a certain size. I’m pretty sure that there needs to be one or more settings adjusted on the Ollama side (like the context size e.g.) but haven’t investigated further so far. Also a different model might make sense. In general Ollama would be a good choice if the model fits into the GPU’s VRAM. That makes processing the document(s) way faster.
Be aware that with Default (SentenceTransformers) no GPU will be used and on CPU everything is a bit slower…
Set Hybrid Search 6️⃣ to On. This will add Reranking Model 8️⃣ to the settings page. I’ll get back to this setting in just a moment.
For the Embedding Model 7️⃣ I’ve chosen sentence-transformers/all-MiniLM-L6-v2. This needs to be a Sentence Transformers Model (a.k.a. SBERT). On the SBERT site you find a list of models to choose from.
Use the Massive Text Embedding Benchmark (MTEB) Leaderboard as an inspiration of strong Sentence Transformer models.
But the documentation also has the following hints:
- Model sizes: it is recommended to filter away the large models that might not be feasible without excessive hardware.
- Experimentation is key: models that perform well on the MTEB leaderboard do not necessarily do well on your tasks, it is crucial to experiment with various promising models.
I also only considered Open models and of course I’m only interested on Sentence Transformers. From Model sizes I deselected >1B. Then the leader board looks like this:
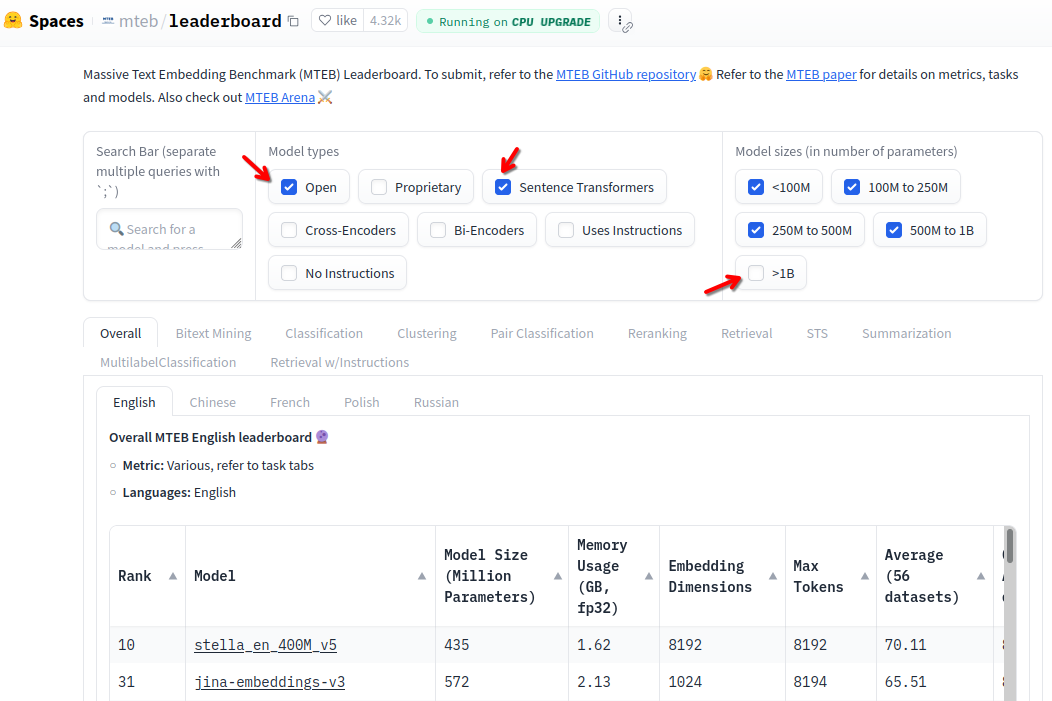
So back to the configuration screen: A good starting point for a model is all-MiniLM-L6-v2 as mentioned above. The description states: All-round model tuned for many use-cases. Trained on a large and diverse dataset of over 1 billion training pairs.. The model is pretty fast and the results are looking good according to my testing.
Below the text field value for the Embedding Model 7️⃣ there is one Warning:
- Warning: If you update or change your embedding model, you will need to re-import all documents.
Later I’ll add a few documents that I want to ask questions. These documents end up in a Vector database. But of course every model stores the processed data differently. If you change the Embedding Model later you need to re-import all your documents as the warning stated above. So start with a small, representative set of documents and experiment before you process a large document collection.
For the Reranking Model I’ve chosen Xenova/bge-large-en-v1.5. It uses about 1.25 GByte of RAM. In the context of Retrieval-Augmented Generation (RAG), Hybrid Search and Reranking Model are concepts that aim to improve the accuracy of retrieving the most relevant documents from your collection so that the AI has better content to work with during responses. Hybrid search is a combination of two approaches to information retrieval: traditional keyword-based search (similar to what ElasticSearch does e.g.) and vector-based search (semantic search). Here’s a simple breakdown:
- Keyword-based search: Matches words in your query with exact or similar words in your documents. It’s effective for finding specific terms but struggles with understanding word meaning or context.
- Vector-based semantic search: Uses AI models to encode the meaning of your query and documents into numerical vectors, allowing it to find documents even if they don’t share exact words but have similar meanings.
A Reranking model is an advanced AI tool that enhances the quality of the results provided by your hybrid search. You can think of it as a second layer of filtering that improves the accuracy of the search results, so you get the best possible documents for your question.
Think of it like this: You’re looking for the best recipe for lasagna in a cookbook. A keyword search would find all the pages that have “lasagna” on them. Semantic search would find pages that might describe lasagna without the word explicitly (e.g., “layered pasta dish”). Hybrid search gets you both. The reranking model is like a chef who reads all the results and tells you which recipe is actually the best for what you’re looking for.
By enabling these options, you’re giving your AI system better tools to find and prioritize the most useful information from your documents, resulting in smarter and more accurate conversations.
You can find reranking models again on the MTEB leaderboard page. Keep the same selections for Model types and Model sizes as above. Only in the tab bar select Reranking instead of Overall.
Further down below I also enabled PDF Extract Images (OCR) (that’s not on the screenshot above). So if there are pictures in a PDF they’ll be extracted and text in the pictures will be processed too.
All the other settings I kept as is. If done click Save on the bottom right.
Upload documents
With everything setup lets start uploading a document that the LLM should consider for answering some questions. A good source for books, text and stuff like that is the Internet Archive. As an oldskool retro guy who started on the Commodore C64 and Amiga I thought Amiga 3D Graphic Programming in BASIC would be a good starting point 😉 There is a text version of that book. You can find it by clicking SHOW ALL in the DOWNLOAD OPTIONS in the right side of the page. The file is called Amiga3dGraphicProgrammingInBasic_djvu.txt. On the command line the file can be downloaded with wget. E.g.:
cd /tmp
wget https://archive.org/download/Amiga3dGraphicProgrammingInBasic/Amiga3dGraphicProgrammingInBasic_djvu.txtFirst a Knowledge base needs to be created:
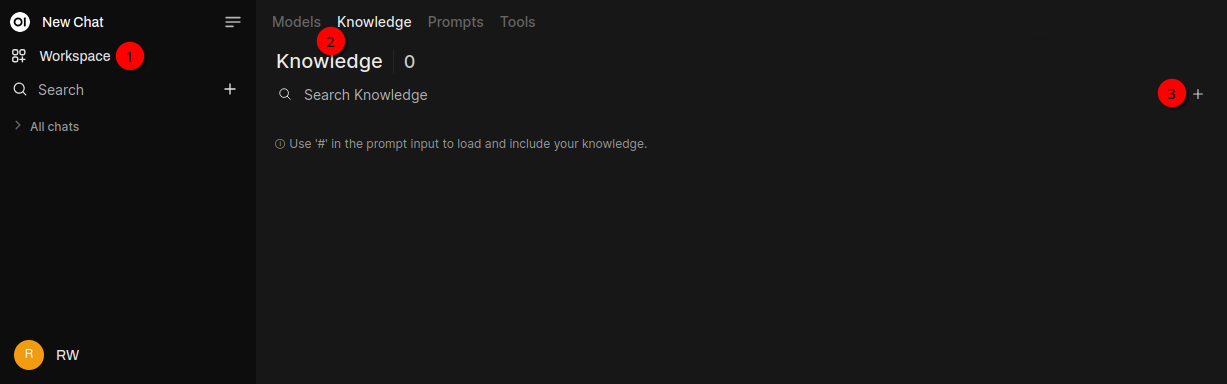
On the left click Workspace 1️⃣, then Knowledge 2️⃣ on the tab bar and + 3️⃣.
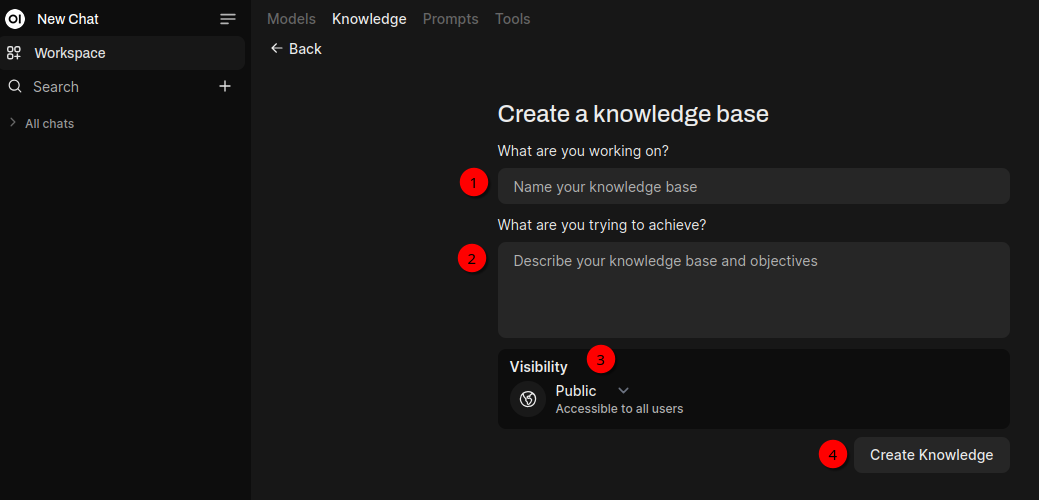
The Knowledge base 1️⃣ needs a name and in my case I’ll call it Amiga. A description 2️⃣ needs to be added too. Visibility 3️⃣ can be set to Public and Private. If you want to make sure that only you can use the documents set Visibility to Private. Next click Create Knowledge 4️⃣.
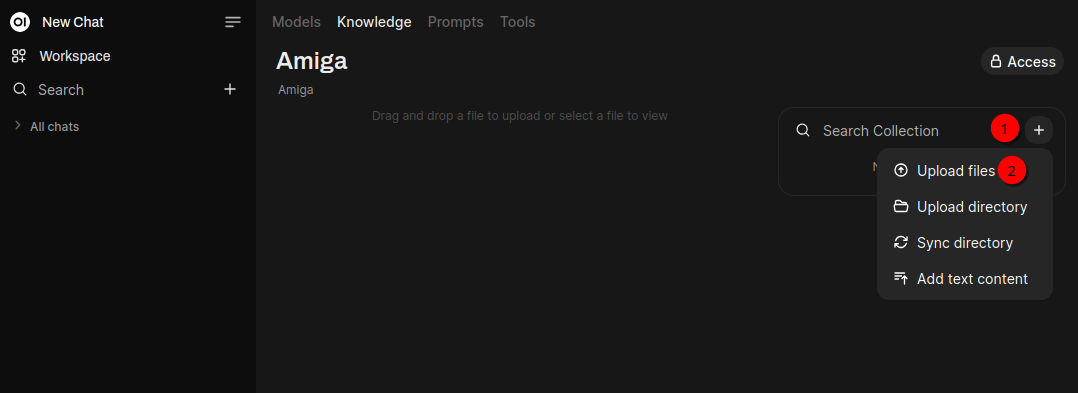
Now the document downloaded above can be uploaded by clicking + 1️⃣ on the right side and Upload files 2️⃣. The processing of this file will take a bit. If done click Knowledge which will show the following screen:
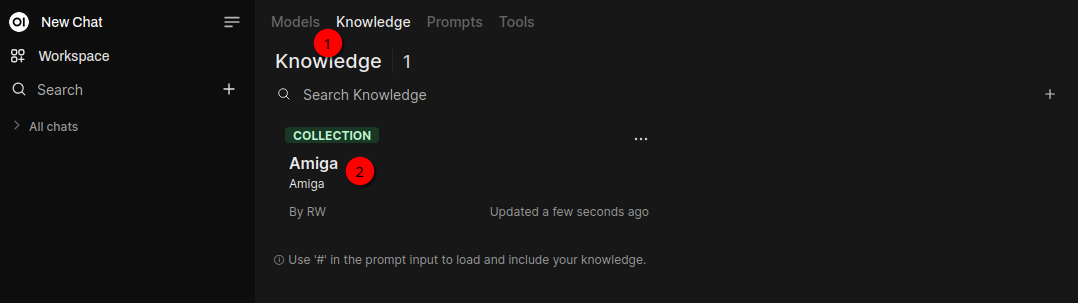
To chat with the Knowledge base (which currently contains only one file):
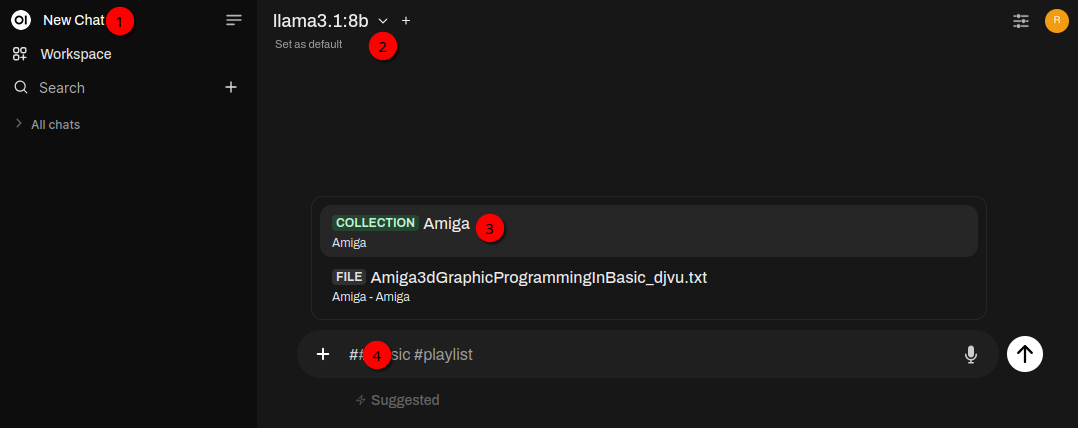
Click New Chat 1️⃣. Select llama3.1:8b 2️⃣ model. In the prompt field type # 4️⃣ This opens a list of currently available Knowledge bases. Select the Amiga 3️⃣ collection. A sample question could be What does the document states about transparency? Please summarize in two to three sentences.. The answer looks like this:
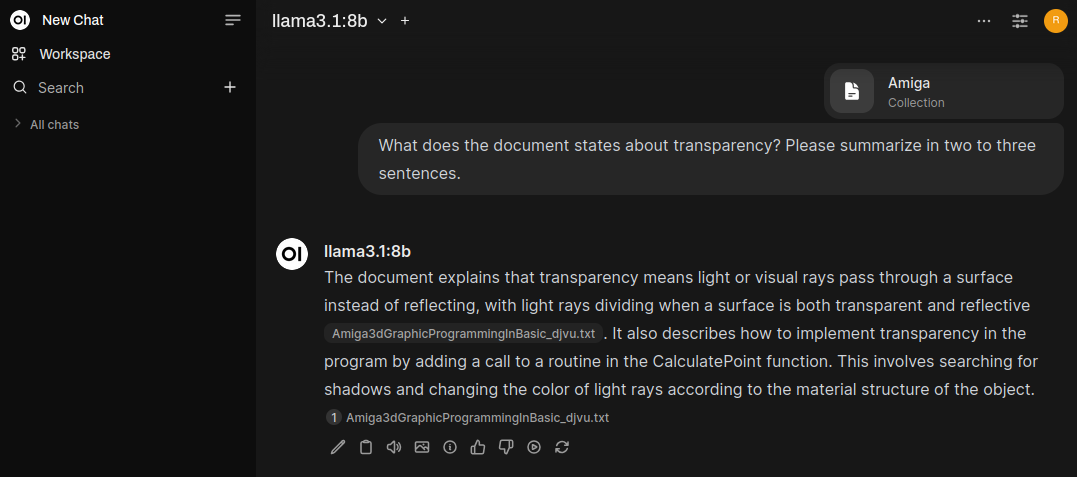
Clicking on Amiga3dGraphicProgrammingInBasic_djvu.txt opens a popup window with the relevant paragraphs the model used for the answer.
That’s it for today!