Turn your computer into an AI machine - Configure and basic usage of Open WebUI

Introduction
In the last part of this blog series I installed and configured Ollama and downloaded some large language models. In the first part I installed Open WebUI which can now be used as a chat frontend for Ollama and the installed models and also as a frontend for the OpenAI API.
Configure Ollama API
Open http://127.0.0.1:8080 (that’s the default port and IP of Open WebUI) in your browser. If you configured a different IP for Open WebUI to listen on then of course use that one.
Hint: You might to restart Open WebUI or do a SHIFT+Reload of the Open Web UI UI to see all changes.
After you login you should see a similar screen:
On the bottom left you can see your username (1). As this is the first user it automatically becomes the “super-user”. If you click on that name a popup appears. The important settings can be made in the Admin Panel (2). On the top you can see Arena Model (3). If you click there you most probably already see the two models llama3.2-vision:11b and llama3.1:8b that were downloaded in the previous blog post. But lets see first where they come from.
Click on Admin Panel as described above and then Settings (1) in the tab bar on the top. This will show the following screen:
Ollama API should be already activated and the connection is set to http://localhost:11434 which is the default. Again, if you have used a different IP, change it here and click Save at the bottom right.
First chat
Now everything is ready to start the first chat with the llama3.1:8b model:
Click on New Chat (1). Next click on Arena Model (2). That will open a pop down menu. Select llama3.1:8b. In the chat text field I enter my first question: Please list all nine planets of the solar system.. This is obviously wrong as Pluto is no longer considered a planet since 2006. But lets see what response I get:
There are actually eight, not nine, officially recognized planets in our
solar system. Here they are:
Mercury
Venus
Earth
Mars
Jupiter
Saturn
Uranus
Neptune
Pluto was previously considered a planet but was reclassified as a dwarf
planet by the International Astronomical Union (IAU) in 2006.
It's worth noting that you might be thinking of a ninth "planet" called Sedna,
which is a trans-Neptunian object located beyond the orbit of Neptune.
However, Sedna does not meet the IAU's criteria for a full-fledged planet
and is still considered a dwarf planet candidate.
Here are all the officially recognized planets in our solar system, plus
some additional objects that might be worth mentioning:
Officially recognized planets: Mercury to Neptune
Dwarf planets (including Pluto): Ceres, Pluto, Eris, Haumea, Makemake,
Sedna
Other notable objects: Moon, asteroids (e.g., Vesta), comets,
Kuiper Belt objects (KBOs)Not bad! In my case printing the output started in less then a second because I already had the model loaded into the GPU VRAM. The very first chat could take a bit longer if the model needs to be loaded into the VRAM - if it was used at all… But in my case chances are high that the GPU was used to generate the output.
Getting GPU statistics
This can be verified in two ways. The first one is running
ollama pscommand. It prints something like this:
NAME ID SIZE PROCESSOR UNTIL
llama3.1:8b 46e0c10c039e 6.9 GB 100% GPU 4 minutes from nowAccording to that output the model used 6.9 GByte VRAM and runs 100% GPU. As I’ve 16 GByte VRAM using this model still allows me to load an additional model into the GPU VRAM of about 8 GByte size (leaving a bit of overhead). That becomes relevant later if I need two models - one for generating text and another for generating images. But as you can see about 7 GByte of data needs to be transferred from the harddisk to the GPU’s VRAM via the PCIe bus. So the faster your PCIe bus is the faster the model gets ready to be used. AFAIK most of the graphics cards are only PCIe 4.0 compatible and none use PCIe 5.0 at the moment (maybe the new Nvidia RTX 5xxx will do so). But if possible put the graphics card into a PCIe 4.0 x16 slot and not in a x8 slot. As I’ve two cards both PCIe 4.0 slots became only x8.
The other command is
nvidia-smiThis needs to be run while the text is generated to get the correct values. The output looks like this:
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.120 Driver Version: 550.120 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4080 ... Off | 00000000:06:00.0 Off | N/A |
| 0% 47C P2 43W / 320W | 6303MiB / 16376MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 837016 C ...unners/cuda_v12/ollama_llama_server 6296MiB |
+-----------------------------------------------------------------------------------------+This output states I’m using 6303MiB (so around 6.2 GByte) VRAM out of the available 16376MiB. There is a slight difference between ollama ps and nvidia-smi of about 0.5 GByte. I currently can’t tell why as the GPU is really only used by ollama. During text generation the card used 43W power (320W is max - which it will indeed use when generating images later 😉). The temperature was at 47C (Degree Celsius). You can also see the process that used the GPU memory which is again ollama as expected.
OpenAI integration
Sometimes a local model might not be good enough. With Open WebUI you can easily also use models from OpenAI (the ChatGPT guys) like the ones listed in the models overview.
Create OpenAI account and API keys
To use them you first need a OpenAI account. You can sign up here. The account itself doesn’t cost money but of course using the models do. But using OpenAI API isn’t that expensive (see OpenAI pricing) if you do some chatting every now and then. I’ve added a 10$ credit in April 2024 and still have 7$ left 😉 I’m using OpenAI API about 5-10x a day. The story is a bit different if you generate images with DALL-E e.g. I’ve set a limit of 20$. I get a warning if I reach that limit to avoid surprises. Once you have an OpenAI account you can generate an API key here.
Add OpenAI key to Open WebUI
With that OpenAI API key we can configure a connection to OpenAI:
Click on your username on bottom left (1) and Admin Panel in the popup that appears. In the tab bar on the top click Settings (2). Insert your API key in the API Key text field (3). Finally click Save (4) on the bottom right.
Models to start with
If you then click on New Chat on the upper right and then on the model list you’ll see a lot more models and not just the self-hosted llama3 ones that were added earlier. If you care about pricing gpt-3.5-turbo or gpt-4o-mini are good starting points. The later one also has vision capabilities. One use-case for this is the integration of text and image data, allowing the model to generate responses that take into account both textual input and visual context. So you can upload a picture (e.g. by clicking the + left to the chat text field) and ask the model to “describe what’s on that picture”. This is also possible with the self-hosted llama3.2-vision:11b model. You can play around by choosing different models asking the same question to see which one gives you the best answer and offers the best price for the output.
Create images with DALL-E
Before I’ll later add ComfyUI integration to generate images with self-hosted models lets configure Open WebUI to generate images with OpenAI’s DALL-E. Again this of course costs money 😉 Please see OpenAI pricing for more information.
First we again need the OpenAI key that was generated above.
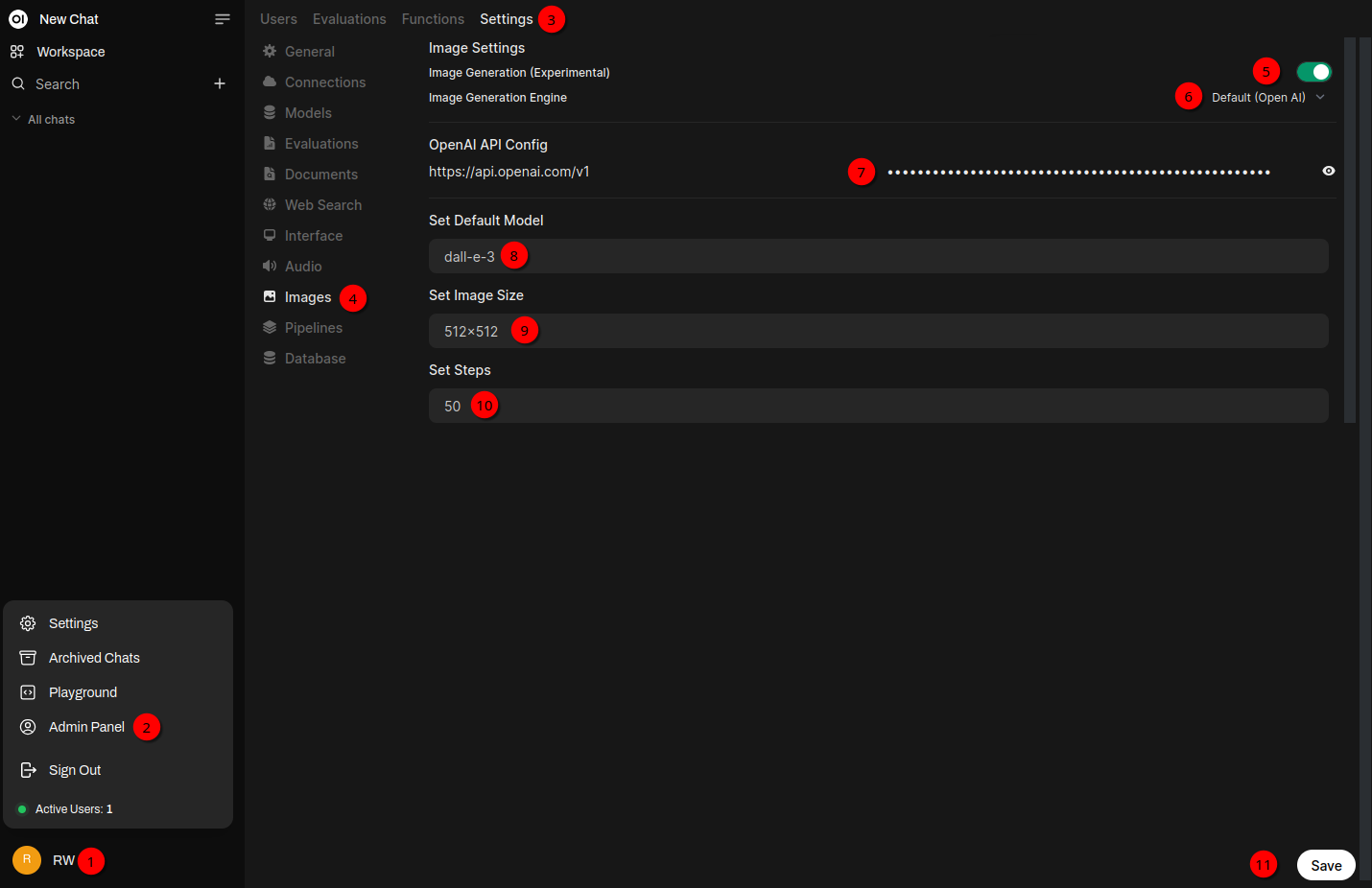
Click your username on the bottom left (1) and Admin Panel (2). On the top click Settings (3) in the tab bar. Click on Images (4). Enable Image Generation) (5). For Image Generation Engine (6) Default (Open AI) is already selected (later I’ll change this to ComfyUI for generating with self-hosted models). Insert the API key into the API key field (7). Click into the Set Default Model field (8) and type d. By doing so you should get a pop up with DALL-E 3 and DALL-E 2 as options. For now select DALL-E 3. For Set Image Size (9) please change to 1024x1024 as this is one of the supported images sizes. For Set Steps (10) I’ll just keep the default. Click Save (11) at the bottom right.
Hint: Changing the size of an image from 1024x1024 to 1024×1792 or 1792×1024 basically doubles the price to generate the image. If you stay with 1024x1024 you can use Upscayl utility later to upscale the image without further costs. This normally works pretty good and you hardly see a difference.
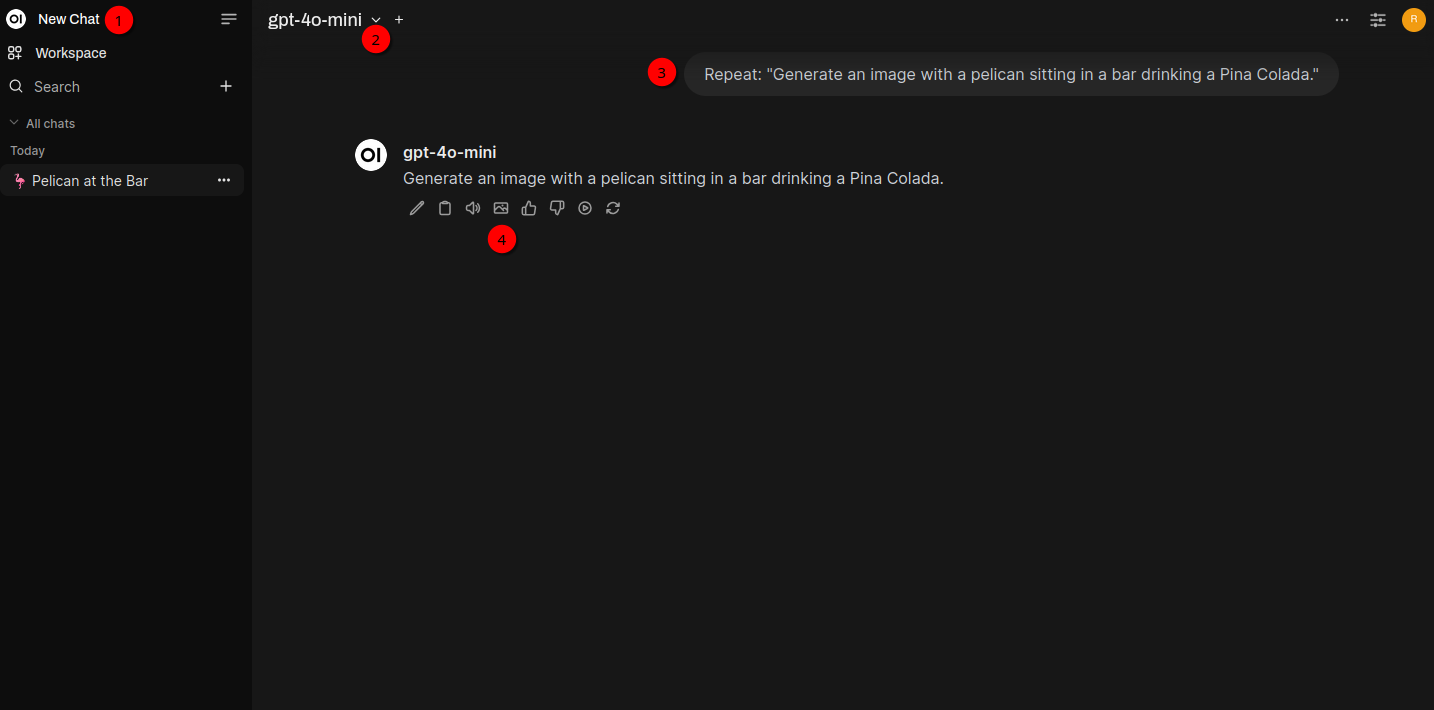
Generating an image with Open WebUI is a bit special in one regard as you’ll see in a moment 😉 Click on New Chat (1) on the upper left and choose gpt-4o-mini (2) as model. In the chat text bar (3) insert this text: Repeat: "Generate an image with a pelican sitting in a bar drinking a Pina Colada.". So for now I really just want the model to repeat the exact text I wrote. Repeat: is the important keyword here. The reason for that is the little icon which you get below the repeated text (4). If you click on that one, DALL-E will generate an image for you like the one below (that will take a few seconds):

Creating new images from a book cover
While already on image generation: In the next chapter I’ll use the book Amiga 3D Graphic Programming in BASIC and ask the models questions about the content of the book. The book cover shows an image with some spheres that were generated using ray tracing. I wanted to have a similar image. So I first created a screenshot of the book cover and used the llama3.2-vision:11b model to describe what’s on the picture. For this click New Chat, select llama3.2-vision:11b model and upload the image using + in the chat prompt. The chat prompt is: Please describe what’s on the picture and print the text of the book cover.:
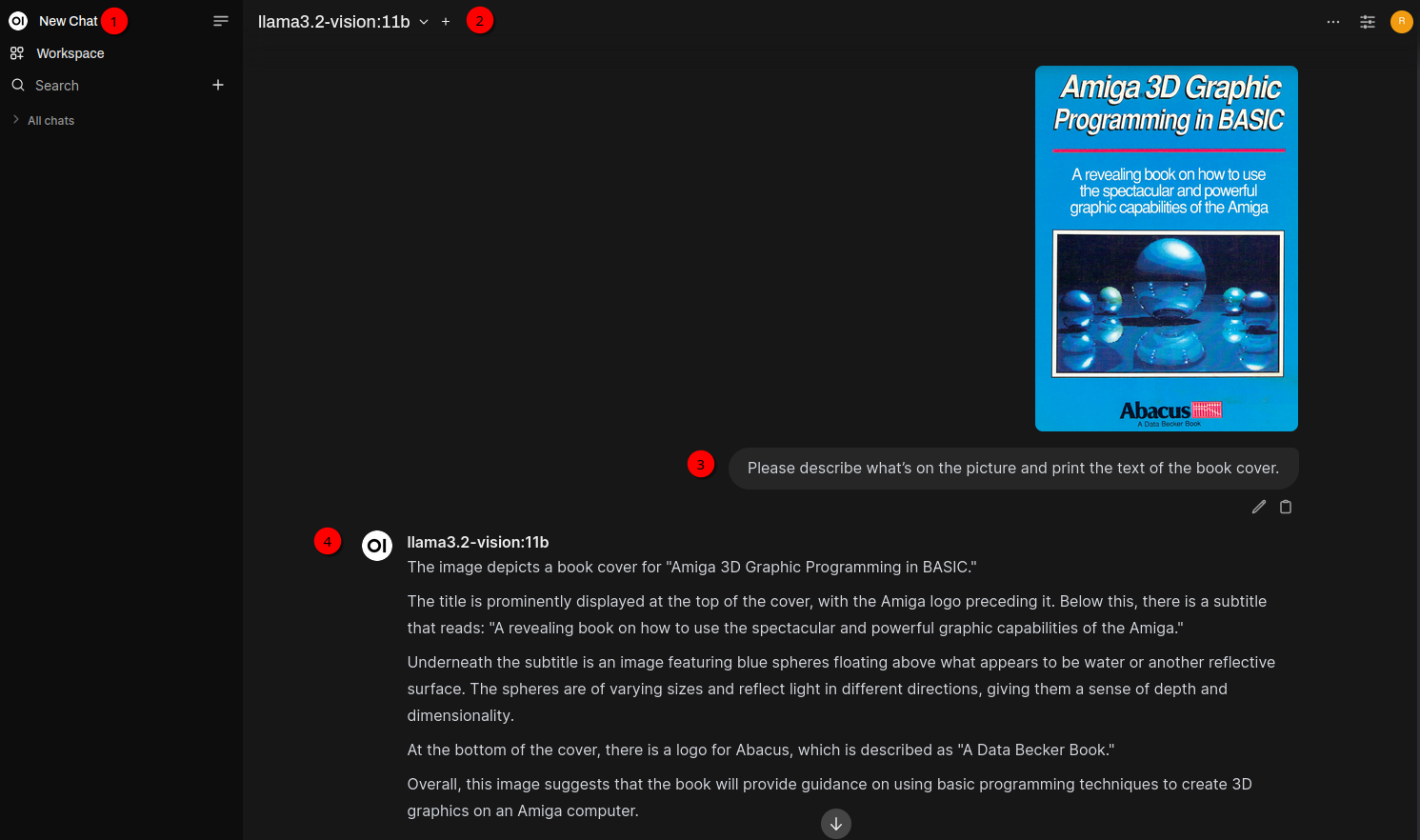
The next chat prompt is: Please describe the picture on the book cover as detailed as possible. You can use the text of the book cover for your calculation but don’t mention anything about the text on the book cover in your response. Also the response should be in a form that makes it easy for DALL-E 3 to generate a new image out of your response..
This will create the following response:

Clicking the Generate Image pictogram 1️⃣ will create the following picture:

Not that bad 😉
In the next blog post it’s all about RAG (Retrieval-Augmented Generation) aka “chat with your documents”.