Turn your computer into an AI machine - Using DeepSeek-R1 with Ollama and Open WebUI

Introduction
So everybody is talking about DeepSeek-R1 model right now, right? 😉 And of course we want to try it out. And that’s actually no problem with Open WebUI and Ollama - at least when you’ve enough VRAM 😉 Otherwise you need to bring quite some time with you - if you’re not on a Mac at least.
There were some security concerns recently for users of the DeepSeek mobile app. Hosting the model locally should mitigate this potential problem - at least you could host it with Ollama on a host with no external network connection 😉 At least you could run a network sniffer to make sure what’s going on. We’ll see what security researchers will find out. On the other hand the requirements to host the really big DeepSeek models are pretty high if it comes to VRAM requirements. But still even smaller versions deliver quite good results.
The model card claims that DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks. The OpenAI o1 models are pretty good but partly also pretty expensive. So having an alternative that is locally hosted is of course nice.
So what’s so special about “reasoning” models like DeepSeek-R1? While normal AI models provide versatile language capabilities, reasoning models add specialized logical processing, making them powerful tools for tasks requiring detailed analysis and structured explanations. E.g. Learning and tutoring: It can help users understand difficult topics by breaking them down into simple steps. They’re particularly effective for tasks where accuracy and clarity are crucial, such as education, problem-solving, or decision-making support.
To maximize the effectiveness of your interactions with the DeepSeek-R1 reasoning model, consider implementing the following five strategies:
- Clarify and Structure Your Requests : When presenting problems or questions to DeepSeek-R1, break them down into clear, logical components. This helps the model process the information more effectively and provides a structured foundation for its reasoning.
- Utilize Step-by-Step Guidance : Encourage the model to explain its thought processes by asking it to detail each step of its reasoning. This can be done by using prompts like “Please walk me through your reasoning step-by-step” or “How did you arrive at that conclusion?”
- Handle Ambiguity with Precision : If the model’s response is unclear or ambiguous, refine your questions to provide additional context or clarify the problem. This can help guide the model towards more accurate and relevant answers.
- Provide Constructive Feedback : If the model’s response is incorrect or unsatisfactory, offer specific corrections or hints. Phrasing feedback in a constructive manner can assist the model in improving its future responses.
- Optimize Input Efficiency : Structure your requests to be as concise and precise as possible while still providing all necessary details. This can help in receiving faster and more accurate answers, leveraging the model’s reasoning capabilities efficiently.
Try to avoid open ended questions. Being precise helps a lot already.
Prerequisites
If not done so please read the follow blog posts to setup and configure Ollama and Open WebUI which is needed:
Also make sure that you’ve Ollama upgraded to the latest version (see Download and install Ollama). The same is true for Open WebUI (see Upgrading Open WebUI).
Install DeepSeek-R1 model
With Ollama installed you now need to make some kind of decision and that mainly depends (as basically always) on your GPU’s VRAM. My NVIDIA 4080 SUPER has 16 GByte VRAM. For me that means I can run deepseek-r1:14b. That model uses about 10 GByte of VRAM and therefore easily fits into my VRAM. That’s important if you want to receive the response to your question while still being alive 😄 Depending on the complexity of the question the answer takes only a few seconds.
I also tried deepseek-r1:32b. That one might fit into the VRAM of a 4090. If not enough VRAM is available, Ollama loads the model in to “normal” computer RAM - at least partly. If you have at least 30 GByte of RAM and not much other programs loaded you can give that model a try too. But it makes really no fun. For me the answer took over two minutes for the same question on my AMD 3900X with 12 cores. Maybe newer CPUs are able to do better here.
That said you can download these models:
- 1.5b
- 7b
- 8b
- 14b
- 32b
- 70b
- 671b
Of course - and also as usual - the bigger the model the better answers you get - but that doesn’t mean that smaller models are not useful.
So after you’ve decided on the model you want to use you can download it. As said I’m using the 14b model (change accordingly):
ollama pull deepseek-r1:14bRestart Ollama:
sudo systemctl restart ollamaUsing the model in Open WebUI
Open your browser and open Open WebUI at http://localhost:8080 (that’s the default port I used so far - otherwise change accordingly). Reload the webpage to be sure to have the latest data loaded.
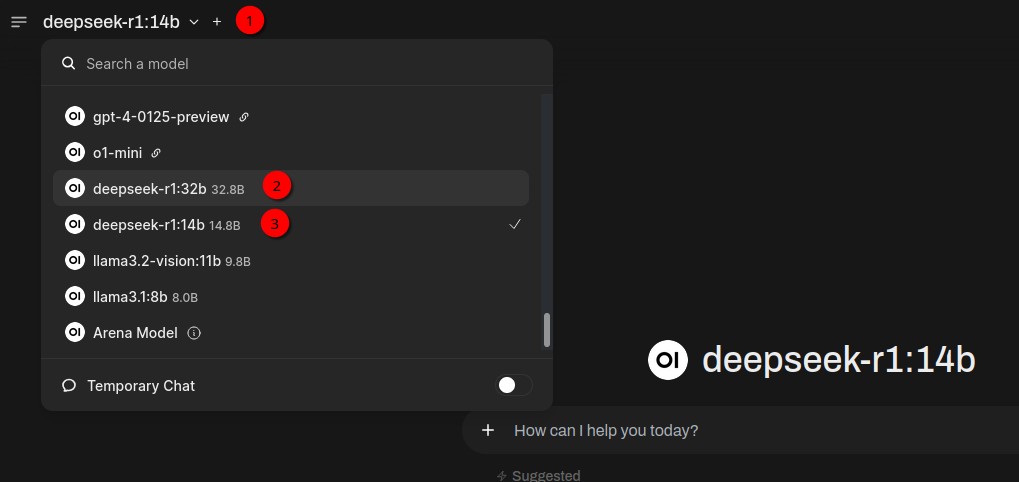
If you click New Chat at the top left and then click on the model list (1) you should see the DeepSeek model you’ve downloaded. In my case that’s deepseek-r1:32b (2) and deepseek-r1:14b (3) because I downloaded both:
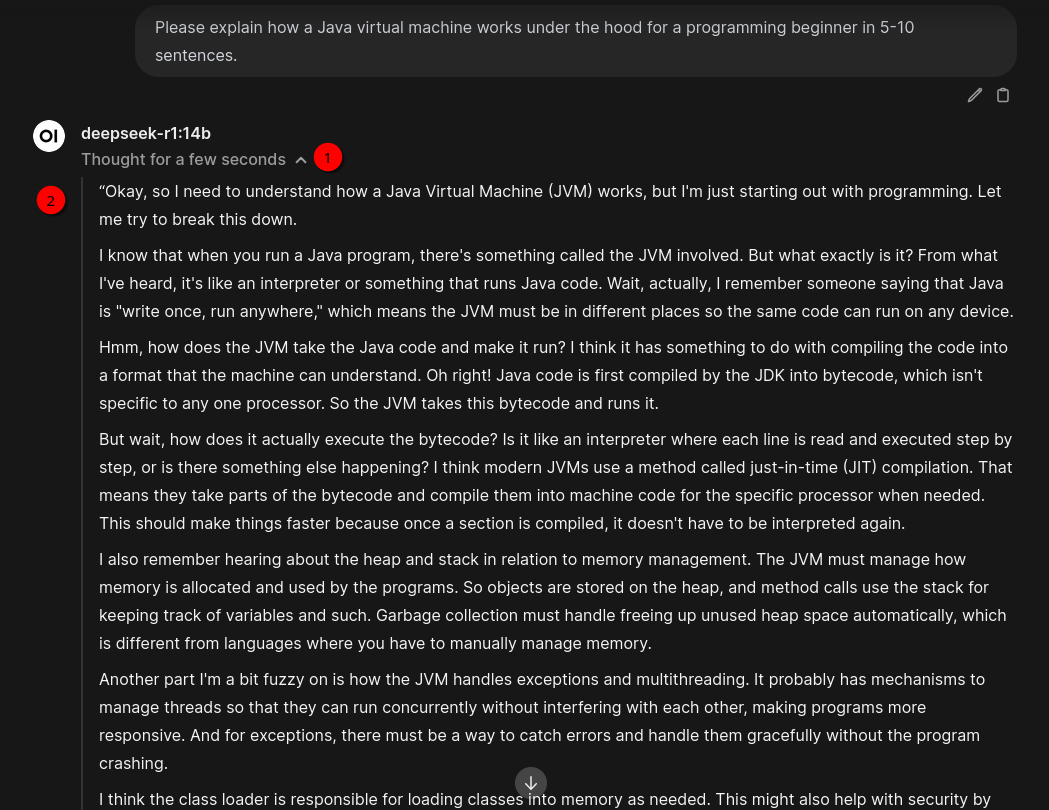
Since reasoning models should be good in explaining things I tried the following question (1):
Please explain how a Java virtual machine works under the hood for a programming beginner in 5-10 sentences.
Now you’ll see Thinking (2) for a few seconds if the model fits into GPU’s VRAM. If not it most probably will take a few minutes. The result looks like this (3):
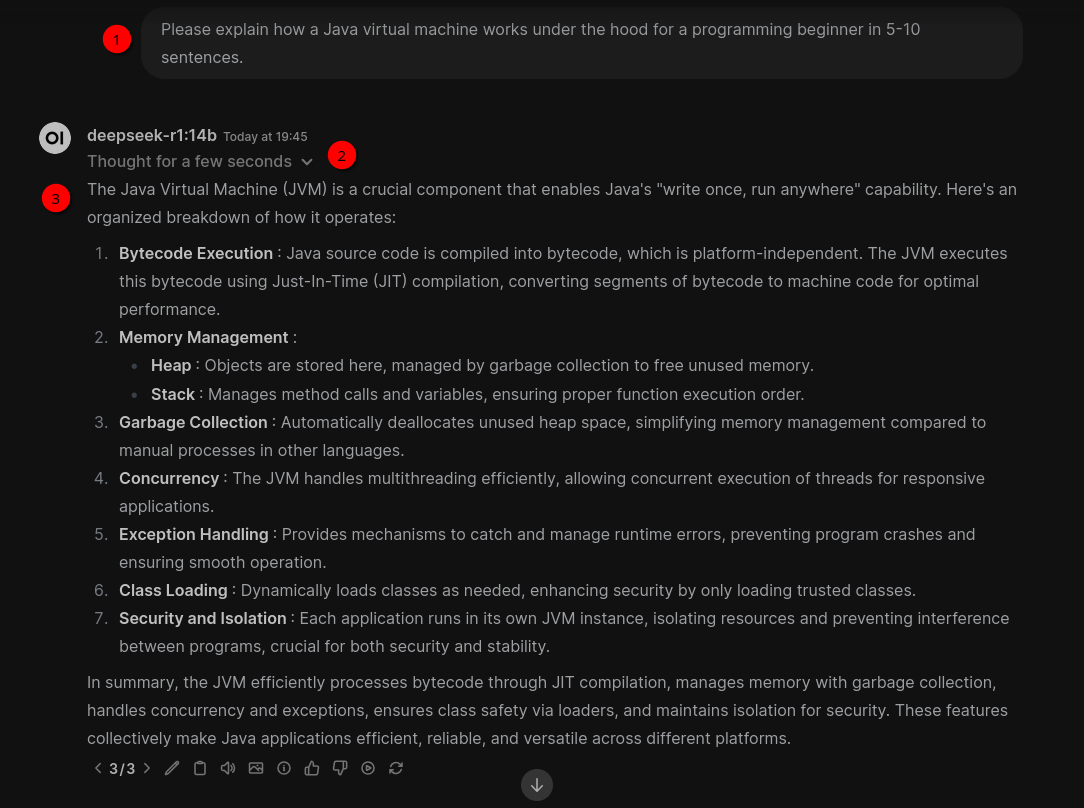
After the result is displayed you can click on Thought for a few seconds (1) and you’ll get some text where the model explains how it got to the answer (2). This is a bit like humans are thinking when solving a problem: